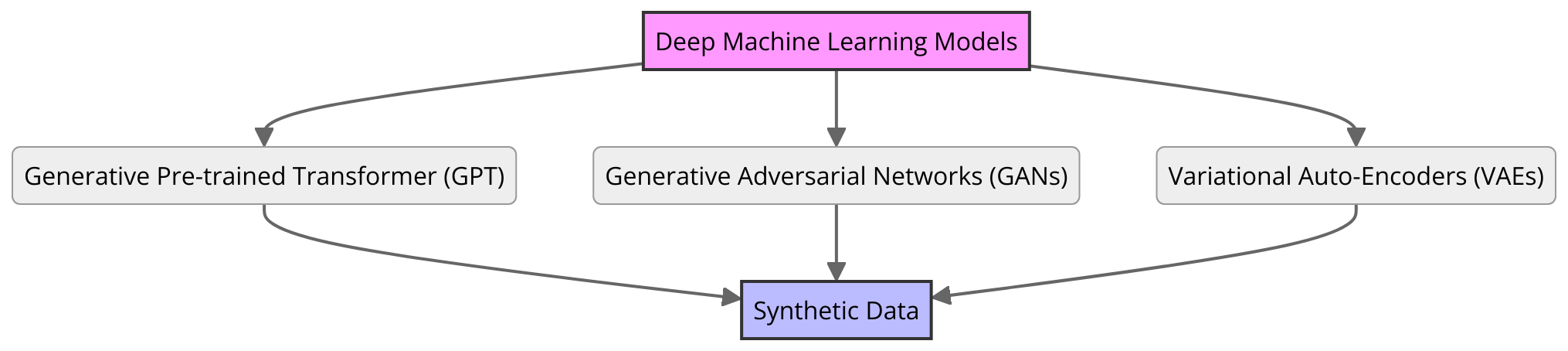
Synthetic data is very important for industrial uses because of several key reasons:
Here is a mindmap diagram illustrating the importance of data synthesis for industrial
applications, specifically for fine-tuning Large Language Models (LLMs):
Data synthesis helps generate diverse datasets where real-world data is limited or hard to collect.
For example, in industries such as healthcare, synthetic patient data can be created to train models
without compromising privacy. This approach allows for a more comprehensive dataset that models can
learn from, enhancing their ability to generalize across different scenarios.
Data synthesis can help reduce model bias and increase its generalization capabilities, By generating
synthetic data that covers rare or underrepresented scenarios.
For Example, in autonomous vehicle development, synthetic data can simulate rare driving conditions
(like extreme weather which real-data is more rare) to ensure the model performs well in a variety of situations, thus improving safety
and reliability.
Data synthesis can significantly speed up the development cycle of LLMs by reducing the time and costs
associated with data collection and labeling. For example, for companies developing natural language
processing (NLP) applications, synthetic data can quickly provide the diverse linguistic input needed
for training, enabling faster iteration and deployment of models.
By generating synthetic datasets that exclude personally identifiable information and sensitive data, user privacy is effectively safeguarded. These datasets can be used for research and development purposes.
Moreover, generative models provide the advantage of generating novel training data that can significantly improve real-world datasets. This method is especially beneficial when obtaining more real data is expensive or time-consuming.
In situations where access to authentic data is constrained or inadequate, generative models offer a viable solution, enabling researchers and developers to manipulate data representations for their research or applications.
Attention
When creating and utilizing synthetic data, it’s essential to be mindful of its accuracy, potential biases, privacy concerns, the risk of overfitting, the expenses involved, and adherence to legal standards.
Now that we discussed the importance of generating synthetic datasets, We will introduce multiple techniques to generate synthetic data, out of which these are the most prominent:
Sampling from a distribution is a widely used method in synthetic data generation, where numbers are selected from a statistical distribution to mimic real-world data patterns. Using Python and the NumPy library, one can easily generate datasets that adhere to a specified distribution, such as a normal distribution.
An example of this is generating a dataset with values normally distributed around a mean of 0 and a standard deviation of 1.
Agent-based modeling is a simulation technique where individual agents interact with each other in a complex system. ABM is useful for examining interactions between agents such as people, cells, or computer programs. Python packages such as Mesa can quickly create agent-based models using built-in core components and visualize them in a browser-based interface.
For example simulating predator-prey dynamics in an ecosystem.
Note
Using effective prompt strategies can steer the model to produce better, consistent, and more factual responses.
Prompt:: Produce 10 exemplars for sentiment analysis. Examples are categorized as either positive or negative. Produce 2 negative examples and 8 positive examples. Use this format for the examples: Q: <sentence> A: <sentiment>
Output::
Q: I just got the best news ever! A: Positive
Q: We just got a raise at work! A: Positive
Q: I’m so proud of what I accomplished today. A: Positive
Q: I’m having the best day ever! A: Positive
Q: I’m really looking forward to the weekend. A: Positive
Q: I just got the best present ever! A: Positive
Q: I’m so happy right now. A: Positive
Q: I’m so blessed to have such an amazing family. A: Positive
Q: The weather outside is so gloomy. A: Negative
Q: I just got some terrible news. A: Negative
This is very useful. We actually use this example for a different test in another section of the guides.
Note
In our case, we generated synthetic data from GPT-4, by the use of the following prompt:
Prompt::
Instruction: As an industrial engineer with extensive expertise in your field, your task is to generate a synthetic dataset that accurately reflects the complexities and nuances of industrial engineering.
Input: generate synthetic data about production to be near factual, generate real industrial situations.
Output: Json file <input, context, output> and the number of questions is 500.
The output was our json file containing synthetic data.
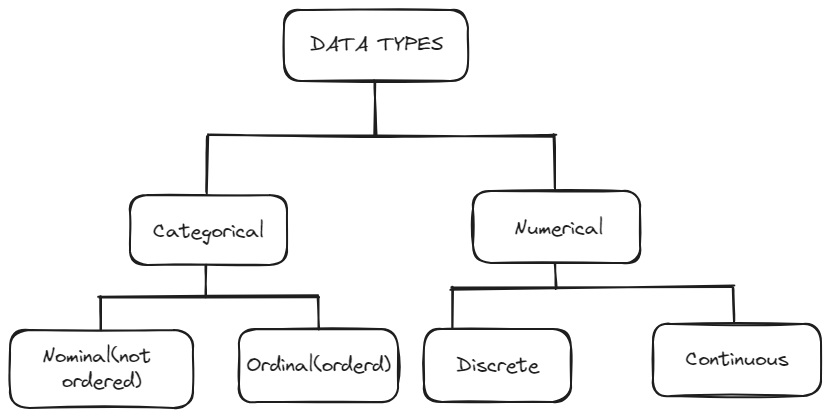
Data is information collected or generated for analysis and interpretation. It encompasses a wide range of formats, including numerical values, textual content, images, and more. In the realm of computing and analysis, data serves as the cornerstone for deriving insights, facilitating informed decision-making, and driving innovation.
Data preprocessing is a pivotal phase in our pipeline, essential for achieving high-quality results. It encompasses refining raw text data to ensure smoother training, faster convergence, and superior model performance. By standardizing input data and employing specialized techniques tailored for large language models, we effectively reduce complexity and enhance overall efficiency.
Data cleaning is a fundamental aspect of data pre-processing for training LLMs. This technique involves identifying and rectifying inaccuracies, inconsistencies, and irrelevant elements within the raw text data.
In any dataset, missing values can crop up when certain observations or features lack data. These gaps pose a significant challenge, potentially skewing predictions and introducing bias into our models. To prevent this, we need to address missing values effectively, ensuring our predictions remain reliable and accurate.
Think of data noise as those pesky distractions – irrelevant or random bits of information that sneak into our dataset. They’re like static on a radio, distorting the true signal and making it harder for our models to predict accurately. By filtering out this noise, we can unveil the genuine patterns hiding within our data and make more reliable predictions.
Consistency checks are like quality control for data, making sure everything follows the same formats and rules. When data doesn’t match up due to errors or glitches, it can cause confusion and inaccuracies in model training.
Duplicates in data often stem from errors during data entry or glitches in the system. These duplicates can skew the distribution of data and result in biased model training. By eliminating duplicates, we ensure the dataset is more accurate and representative, thereby improving the performance of the LLM.
Removing noise from text and standardizing it are essential for enhancing the quality of our textual data, which in turn improves the performance of natural language processing tasks. Various techniques and tools are available to address these challenges.
To effectively manage this task, we can utilize several libraries that are designed to help clean and standardize text data. These libraries provide robust functionalities for preprocessing text, making it cleaner and more uniform for subsequent analysis.
Lowercasing is a text preprocessing step where all letters in the text are converted to lowercase. This step is implemented so that the algorithm does not treat the same words differently in different situations.
Punctuation and special characters removal is a text preprocessing step where you remove all punctuation marks (such as periods, commas, exclamation marks, emojis etc.) from the text to simplify it and focus on the words themselves.
Stop-words are the most common words in any language (like articles, prepositions, pronouns, conjunctions, etc) and do not add much information to the text. Examples of a few stop words in English are “the”, “a”, “an”, “so”, “what”.
For this technique, we will use the NLTK library.
This preprocessing step is to remove any URLs present in the data.
It’s important to remove HTML tags from the text data. Indeed, if we work with text data obtained from HTML sources, the text may contain HTML tags, which are not desirable for text analysis.
Stemming is a linguistic normalization that simplifies words to their base form or root by removing prefixes and suffixes, helping the natural language processing and information retrieval.
Lemmatization simplifies words to their base or root form, known as the lemma, making it easier to analyze a word. The difference between stemming and lemmatization is that the latter transforms words to their standardized form and aims to return a valid word by applying linguistic rules and context.
Warning
The difference between Lemmatization and Stemming is simple :Lemmatization reduces words to their canonical form,while stemming reduces them to their root form
Removing redundant whitespace is an essential step in text preprocessing to ensure a clean and standardized representation of the text. Extra whitespaces can lead to inconsistencies and negatively impact the performance of natural language processing (NLP) tasks.
After preprocessing our data, the next step will be to feed it into our large language model. The concern here is whether our LLM will have a very good understanding of our cleaned data. In this context, we will discuss an important concept known as Tokenization.
Tokenization and word embedding are crucial steps in natural language processing (NLP) that help convert textual data into numerical formats that can be easily processed by machine learning models.
Tokenization, in the realm of Natural Language Processing (NLP) and machine learning, refers to the process of converting a sequence of text into smaller parts, known as tokens. These tokens can be as small as characters or as long as words.
The aim of tokenization is to represent text in a manner that’s meaningful for machines without losing its context.
Word Tokenization: Splits text into individual words.
NLTK (Natural Language Toolkit): Provides functions for word and sentence tokenization along with additional NLP functionalities like stemming, lemmatization, and POS tagging.
# Importing necessary functions from NLTKimportnltkfromnltk.tokenizeimportword_tokenize,sent_tokenize# Download the NLTK data files (only the first time)nltk.download('punkt')nltk.download('averaged_perceptron_tagger')nltk.download('wordnet')# Input texttext="Hello world. How are you?"# Word tokenizationwords=word_tokenize(text)# Sentence tokenizationsentences=sent_tokenize(text)# Part-of-Speech (POS) taggingpos_tags=nltk.pos_tag(words)# Lemmatizationfromnltk.stemimportWordNetLemmatizerlemmatizer=WordNetLemmatizer()lemmas=[lemmatizer.lemmatize(word)forwordinwords]# Output resultsprint("Word Tokenization:",words)print("Sentence Tokenization:",sentences)print("POS Tagging:",pos_tags)print("Lemmatization:",lemmas)
spaCy: Efficient tokenization and additional NLP functionalities such as POS tagging, named entity recognition (NER), and dependency parsing.
# Importing spaCy and loading the English modelimportspacy# Load the small English modelnlp=spacy.load("en_core_web_sm")# Input texttext="Hello world. How are you?"# Processing the text through the spaCy pipelinedoc=nlp(text)# Extracting tokenstokens=[token.textfortokenindoc]# POS taggingpos_tags=[(token.text,token.pos_)fortokenindoc]# Named Entity Recognition (NER)entities=[(entity.text,entity.label_)forentityindoc.ents]# Dependency Parsingdependencies=[(token.text,token.dep_,token.head.text)fortokenindoc]# Output resultsprint("spaCy Tokenization:",tokens)print("POS Tagging:",pos_tags)print("Named Entities:",entities)print("Dependencies:",dependencies)
transformers: Tokenization for transformer-based models, and access to pre-trained transformer models for tasks such as text classification, named entity recognition, and question answering.
# Importing the BertTokenizer from transformers libraryfromtransformersimportBertTokenizer# Loading the BERT tokenizertokenizer=BertTokenizer.from_pretrained('bert-base-uncased')# Input texttext="Hello world. How are you?"# Tokenizing the text using BERT tokenizertokens=tokenizer.tokenize(text)# Output resultsprint("BERT Tokenization:",tokens)
One-hot encoding is a basic and straightforward method to represent words. Each word in the vocabulary is represented as a binary vector, where only the index corresponding to that word is set to 1, and all other indices are set to 0.
Example: In a vocabulary of three words [“cat”, “dog”, “fish”], the one-hot encodings would be:
- “cat” -> [1, 0, 0]
- “dog” -> [0, 1, 0]
- “fish” -> [0, 0, 1]
Advantages:
- Simple to implement.
- Intuitive and easy to understand.
Limitations:
- High dimensionality: For a large vocabulary, the vectors become very large and sparse.
- No semantic meaning: Does not capture any relationship between words. “cat” and “dog” are as dissimilar as “cat” and “fish”.
Word2Vec is a popular word embedding technique that produces dense, continuous vector representations of words. It uses neural networks to learn the embeddings from large corpora of text. Word2Vec offers two models:
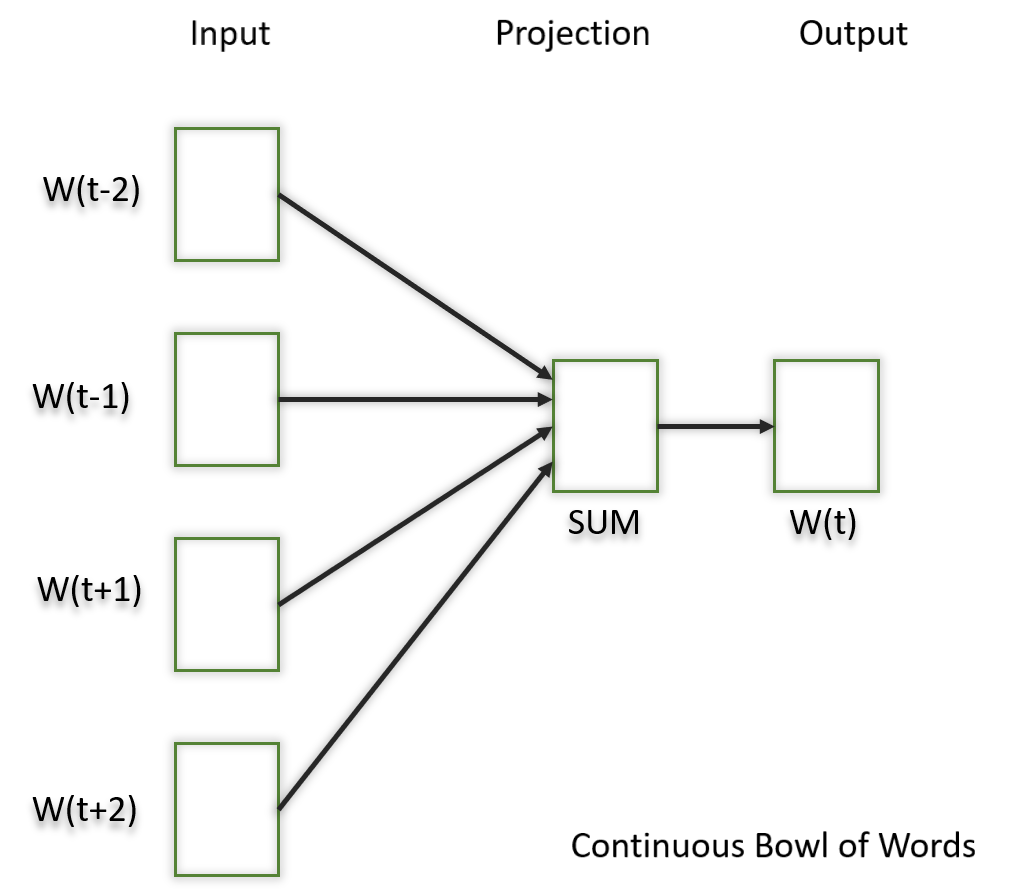
CBOW (Continuous Bag of Words):
- Predicts the target word from the context words.
- Faster and works well with frequent words.
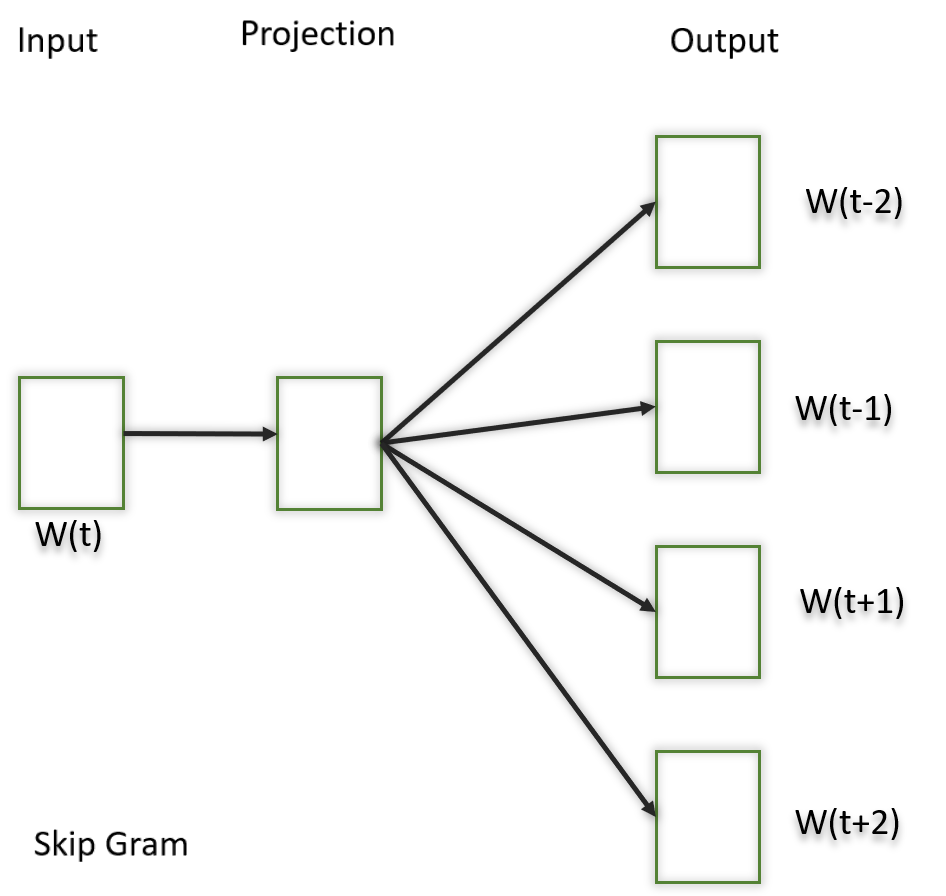
Skip-gram:
- Predicts the context words from the target word.
- Better for smaller datasets and rare words.
CBOW aims to predict a target word based on its context, which consists of the surrounding words in a given window.
It a feedforward neural network with a single hidden layer. The input layer represents the context words, and the output layer represents the target word. The hidden layer contains the learned continuous vector representations (word embeddings) of the input words.
Skip-gram is a slightly different word embedding technique in comparison to CBOW as it does not predict the current word based on the context.This variant takes only one word as an input and then predicts the closely related context words. That is the reason it can efficiently represent rare words.
Bag of Words (BOW) is a simple but powerful approach to vectorizing text. As the name suggests, the bag-of-words technique does not consider the position of a word in a document. Instead, all the words are dropped into a big bag. The idea is to count the number of times each word appears in each document without considering its position or grammatical role.
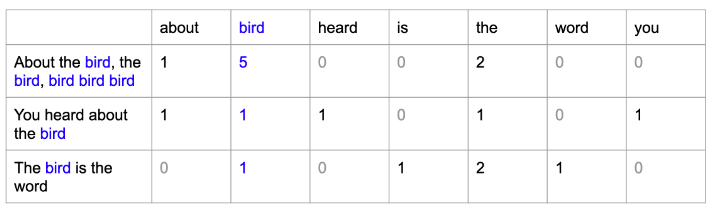
Example: Consider the three following sentences from the well-known Surfin’ Bird song, and count the number of times each word appears in each sentence. Let’s first list all the words in the verses:
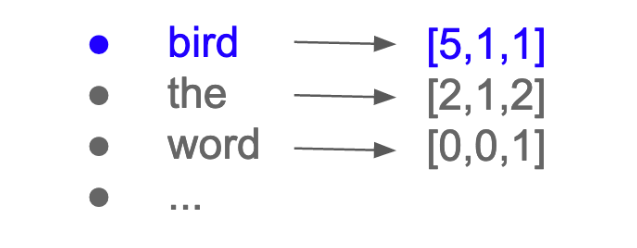
Each word is now associated with its own column of numbers, its own vector:
Note
The matrix calculated on this simple example of three sentences can be generalized to many documents in the corpus. Each document is a row, and each token is a column. Such a matrix is called the document-term matrix. It describes the frequency of terms that occur in a collection of documents and is used as input to a machine learning classifier.
Note that the size of the document-term matrix is: number of documents * size of vocabulary.
The vector size of each token equals the number of documents in the corpus. With this BOW approach, a large corpus has long vectors, and a small corpus has short vectors (as in the Surfin’ Bird example above, where each vector only has three numbers).
Note
A corpus is a set of texts or documents. A document is any distinct text varying in size, format, or structure and can include sentences, paragraphs, tweets, SMS, comments, reviews, articles, books, etc.
4. GloVe (Global Vectors for Word Representation)
GloVe is a word embedding technique that combines the advantages of both matrix factorization techniques and local context window methods. It leverages word co-occurrence statistics from a corpus to learn word vectors.
Example: GloVe creates word vectors based on the frequency of words appearing together in a context window across the entire corpus.
Advantages:
- Captures both global statistical information and local context.
- Efficient and produces meaningful embeddings.
Limitations:
- Context-independent: Similar to Word2Vec, it doesn’t capture different meanings of words in different contexts.
FastText extends Word2Vec by representing each word as an n-gram of characters, which helps in generating embeddings for words that were not seen during training (out-of-vocabulary words).
Example: The word “unhappiness” can be represented as character n-grams [“un”, “unh”, “hap”, “happ”, “ppiness”, “iness”].
Advantages:
- Handles out-of-vocabulary words better.
- Produces more fine-grained embeddings by considering subword information.
Limitations:
- Increased computational complexity compared to Word2Vec.
Title: “Data Cleaning: Overview and Emerging Challenges”
Authors: Ihab F. Ilyas, Xu Chu
Published in: ACM Journal of Data and Information Quality (JDIQ)
Year: 2019
Abstract: This paper provides a comprehensive overview of data cleaning, discussing its importance, the challenges faced, and emerging trends. It delves into various data cleaning techniques, frameworks, and tools.
Title: “Data Cleaning: Problems and Current Approaches”
Authors: Erhard Rahm, Hong Hai Do
Published in: IEEE Data Engineering Bulletin
Year: 2000
Abstract: This paper reviews the data cleaning process, identifies common problems, and evaluates existing approaches to address these problems. It also discusses the integration of data cleaning tools in data warehousing environments.
Title: “A System for Interactive Data Cleaning and Transformation”
Authors: Tamraparni Dasu, Theodore Johnson, Seung Jin Manku, Divesh Srivastava
Published in: IEEE Data Engineering Bulletin
Year: 2002
Abstract: This paper presents an interactive system designed for data cleaning and transformation. It highlights the importance of user involvement in the data cleaning process and demonstrates the system’s capabilities through various case studies.